

|
|
|
Главная страница Взаимодействие нетривиальных процессов процесс 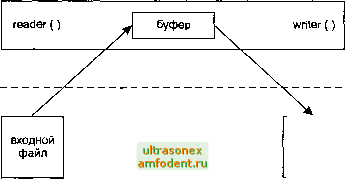 процесс ядро выходной файл Рис. 10.11. Один процесс, считывающий данные в буфер и записывающий их в файл На рис. 10.10 приведена временная диаграмма работы такой программы. Числа слева проставлены в условных единицах времени. Предполагается, что операция чтения занимает 5 единиц, записи - 7, а обработка данных между считыванием и записью требует 2 единицы времени. Можно изменить это приложение, разделив процесс на отдельные потоки, как показано на рис. 10.12. Здесь используется два потока (а не процесса), поскольку глобальный буфер автоматически разделяется между ними. Мы могли бы разделить приложение и на два процесса, но это потребовало бы использования разделяемой памяти, с которой мы еще не знакомы. 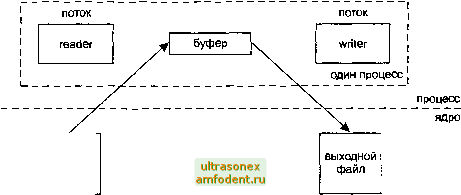 входной файл Рис. 10.12. Разделение копирования файла между двумя потоками Разделение операций между потоками (или процессами) требует использования какой-либо формы уведомления между ними. Считывающий поток должен уведомлять записывающий о готовности буфера к операции записи, а записывающий должен уведомлять считывающий о том, что буфер пуст и его можно заполнять снова. На рис. 10.13 изображена временная диаграмма для новой схемы. входной файл вхсщной файл входной файл считывающий поток О - 1 2 3 4 5 20 - 21 - 22 23 24 25 26 27 28 29 30 31 записывающий поток > read () уведомление записывающего потока буфер write ite () / уведомление считывающего потока > read О уведомление записывающего \ потока буфер write ite ()< уведомление считывающего потока время 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 - 27 28 - 29 - 30 - 31 время выходной файл выходной файл Рис. 10.13. Копирование файла двумя потоками Предполагается, что для обработки данных в буфере требуется две единицы времени. Важно отметить, что разделение чтения и записи между двумя потоками ничуть не ускорило выполнение операции копирования в целом. Мы не выиграли в скорости, мы просто распределили выполнение задачи между двумя потоками (или процессами). В этих диаграммах мы игнорируем множество тонкостей. Например, большая часть ядер Unix выявляет операцию последовательного считывания файла и осуществляет асинхронное упреждающее чтение следующего блока данных еще до поступления запроса. Это может ускорить работу процесса, считывающего данные. Мы также игнорируем влияние других процессов на наши считывающий и записывающий потоки, а также влияние алгоритмов разделения времени, реализованных в ядре. Следующим шагом будет использование двух потоков (или процессов) и двух буферов. Это называется классическим решением с двойной буферизацией; схема его изображена на рис. 10.14. 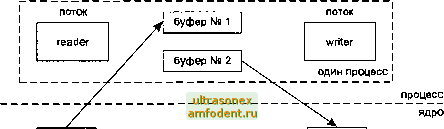 входной файл выходной файл Рис. 10.14. Копирование файла двумя потоками с двумя буферами На нашем рисунке считывающий поток помещает данные в первый буфер, а записывающий берет их из второго. После этого потоки меняются местами. На рис. 10.15 изображена временная диаграмма процесса с двойной буферизацией. Считывающий поток помещает данные в буфер № 1, а затем уведомляет записывающий о том, что буфер готов к обработке. Затем считывающий процесс помещает данные в буфер № 2, а записывающий берет их из буфера № 1. В любом случае, мы ограничены скоростью выполнения самой медленной операции - операции записи. После выполнения первых двух операций считывания серверу приходится ждать две дополнительные единицы времени, составляющие разницу в скорости выполнения операций чтения и записи. Тем не менее для нашего гипотетического примера полное время работы будет сокращено почти вдвое. Обратите внимание, что операции записи выполняются так быстро, как только возможно. Они разделены промежутками времени всего лишь в 2 единицы, тогда как в предыдущих примерах между ними проходило 9 единиц времени (рис. 10.10 и 10.13). Это может оказаться выгодным при работе с некоторыми
|
|
© 2000 - 2025 ULTRASONEX-AMFODENT.RU.
Копирование материалов разрешено исключительно при условии цититирования. |